Back to blog
From Visibility to Action: Why Observability Alone Isn’t Enough
In
Enterprise IT Management
by
Divya CH

Enterprise IT has spent the last decade chasing visibility.
More dashboards.
More metrics.
More alerts.
More tools claiming “single pane of glass.”
And yet, nothing feels under control.
If anything, teams are more overwhelmed than before.
The industry doesn’t have a visibility problem anymore.
It has an execution problem.
When Seeing Everything Changes Nothing
Most modern IT environments can tell you exactly what’s happening.
CPU spikes.
Memory leaks.
Application crashes.
Patch failures.
Network instability.
The data is there. The graphs are there. The alerts are definitely there.
But here’s the uncomfortable reality.
Knowing something is broken is not the same as fixing it.
A slow laptop doesn’t get faster because it showed up on a dashboard.
A failed patch doesn’t resolve itself because it triggered an alert.
A recurring issue doesn’t disappear because it’s been categorized correctly.
Observability gives you information.
It does not give you outcomes.
The Cost of “Insight-Only” Systems
On paper, observability platforms promise control. In practice, they create a different kind of load.
Every alert needs interpretation.
Every anomaly needs triage.
Every issue needs someone to take ownership.
This creates a hidden dependency that most teams underestimate.
Humans become the processing layer.
That doesn’t scale.
As environments grow, three things start to happen:
Alert fatigue becomes normal
Response times stretch despite “real-time” monitoring
Repetitive issues consume disproportionate effort
The system is technically observable, but operationally inefficient.
Why Dashboards Became the Default
There’s a reason the industry leaned so heavily into visibility.
It was the easiest problem to solve.
Collect data.
Visualize data.
Correlate data.
All valuable. None sufficient.
What’s missing is the hardest part.
Decision-making.
Execution.
Accountability for resolution.
That’s where most tools stop.
Action Is the Missing Layer
The next evolution of IT operations is not better visibility.
It is closing the loop.
Detection → Diagnosis → Resolution
Without that final step, the loop is incomplete.
Action means:
Identifying root cause, not just symptoms
Triggering the right fix without waiting for a ticket
Verifying that the issue is actually resolved
Learning from the incident to improve future responses
This is where the real efficiency gains are.
Not in seeing more, but in doing more without manual effort.
A Simple Test
Take any recurring issue in your environment.
Something that shows up every week.
Now ask:
Do we already know this pattern?
Do we already know the fix?
Are we still handling it manually?
If the answer to all three is yes, then the system is broken.
Not technically broken. Operationally broken.
Because the knowledge exists, but it’s not being used to eliminate the work.
Where Most Tools Fall Short
Many platforms have started adding “automation” as a layer.
But in most cases, it looks like:
Static scripts
Rule-based triggers
Manual playbooks
These help, but they don’t change the model.
They still depend on someone:
Defining the condition
Writing the response
Maintaining the logic
That’s still human-driven operations with some assistance.
What’s needed is something more adaptive.
Moving Toward Autonomous Execution
The real shift happens when systems start handling decisions, not just tasks.
That requires combining:
Real-time endpoint signals
Historical behavior patterns
Context across applications and system layers
Continuous feedback loops
At that point, you’re no longer reacting to alerts.
You’re preventing outcomes.
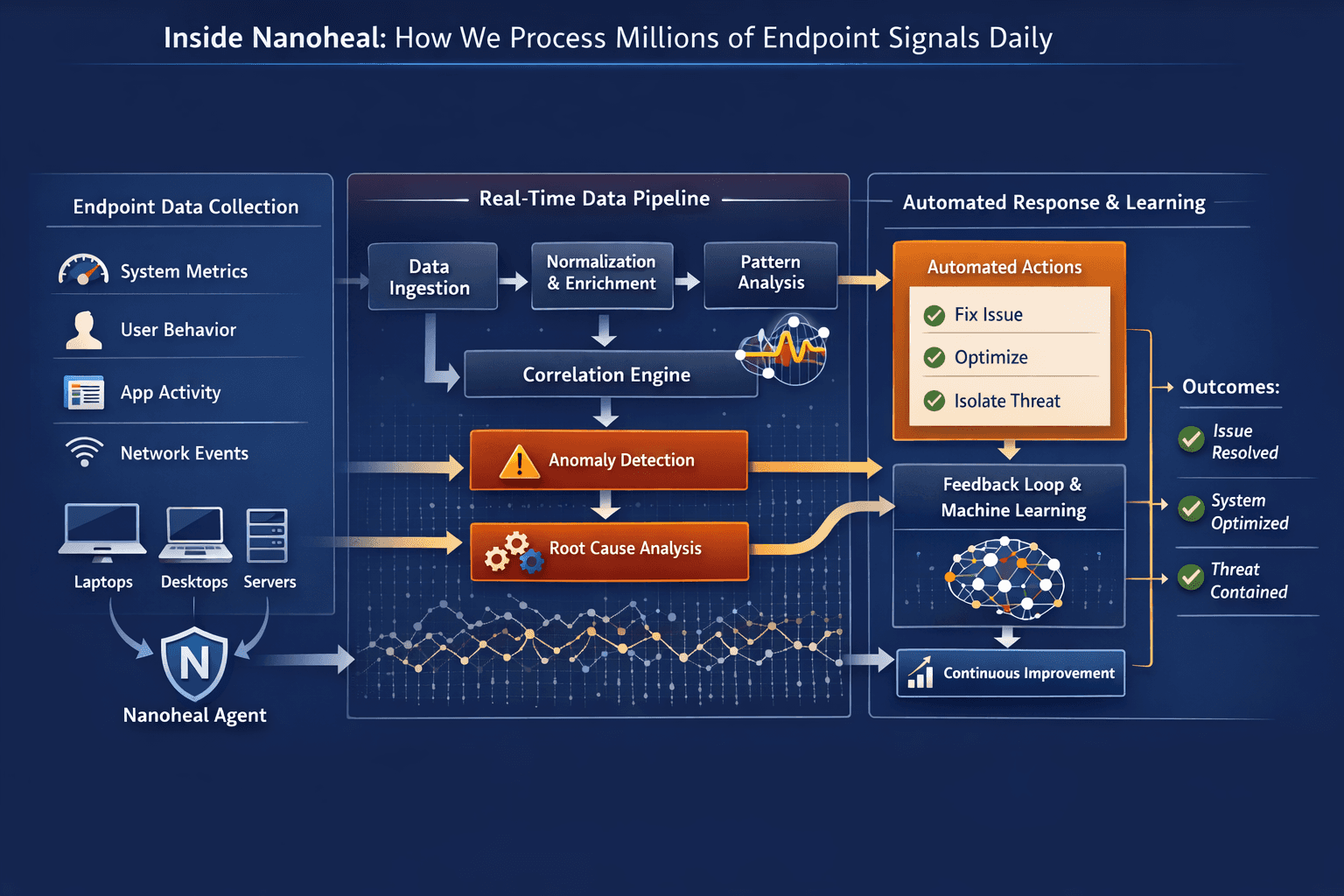
Where Nanoheal Fits In
Nanoheal was built around a simple premise.
If you already know how to fix something, you shouldn’t have to fix it again.
Instead of stopping at visibility, Nanoheal focuses on execution:
Detecting anomalies at the device level before they escalate
Identifying root causes across system, application, and user behavior
Triggering corrective actions automatically
Continuously improving through feedback loops
This turns IT from a monitoring function into a resolution engine.
The difference is subtle in theory, but massive in practice.
Less time spent looking at problems.
More problems disappearing on their own.
The Real KPI Shift
For years, IT has measured success using:
Mean time to resolve
Ticket closure rates
SLA adherence
These are all downstream metrics.
They assume issues will happen.
The next generation of IT teams will measure something else.
Issues prevented
Incidents resolved without human intervention
User disruption avoided entirely
That’s a very different operating model.
Final Thought
Observability solved an important problem. It gave IT teams visibility into complex systems.
But visibility was never the end goal.
It was just the starting point.
The real question is no longer:
“How well can we see what’s happening?”
It’s:
“How much of this can we handle without anyone getting involved?”