Back to blog
Inside Nanoheal: How We Process Millions of Endpoint Signals Daily
In
Digital Transformation
by
Divya CH
It’s easy to talk about automation in theory.
It’s harder to make it work in real environments.
Thousands of devices.
Different usage patterns.
Constant change.
Unpredictable behavior.
At that scale, even simple problems become complex.
What looks like a straightforward issue on one device becomes a pattern across hundreds.
What appears to be noise in isolation becomes a signal when viewed over time.
Making sense of that, and acting on it reliably, requires more than just collecting data.
It requires a system designed to process, understand, and respond continuously.
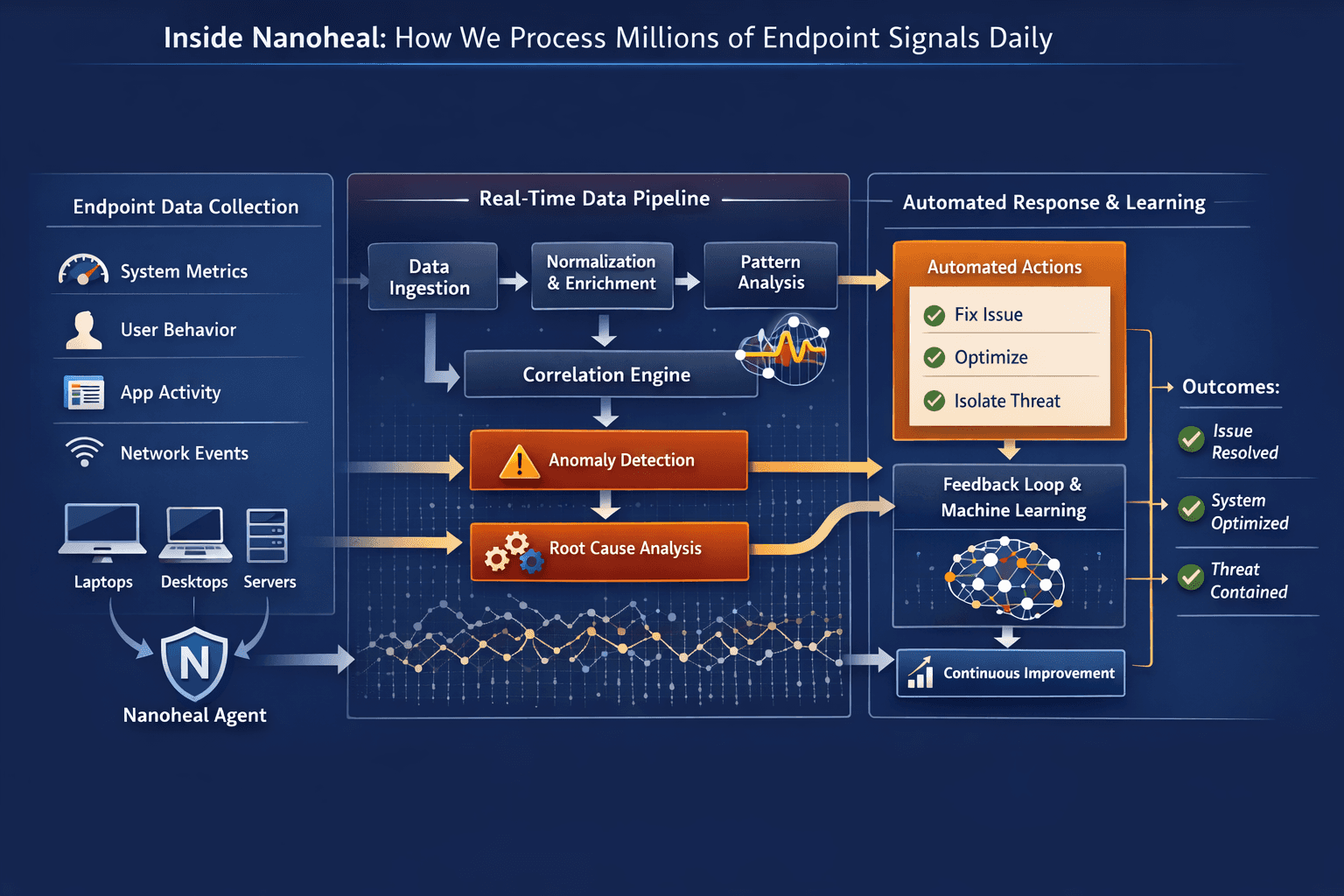
The Nature of Endpoint Data
Endpoint environments generate an enormous amount of information.
System performance metrics
Application behavior
User interactions
Background processes
Network conditions
Most of this data is transient.
A spike here. A delay there. A process behaving slightly differently than usual.
Individually, these don’t always mean much.
The value comes from understanding them in context.
Across time. Across devices. Across patterns.
From Raw Signals to Meaningful Patterns
Processing endpoint data is not just about volume.
It’s about filtering what matters.
At a high level, the system continuously:
Collects signals from endpoints in real time
Normalizes and structures the data
Identifies deviations from expected behavior
Correlates signals across different layers
This is where raw telemetry becomes useful.
Not as isolated events, but as patterns that indicate something changing.
Why Context Matters
A CPU spike is not always a problem.
A memory increase is not always a concern.
These become meaningful only when viewed in context.
Is this normal for this device?
Does it happen at a specific time or under specific conditions?
Is it linked to a particular application or behavior?
Without context, everything looks like noise.
With context, small signals become early indicators.
Real-Time Isn’t Optional
In endpoint environments, timing matters.
An issue detected too late is an issue already experienced.
Which means processing can’t be batch-driven or delayed.
Signals need to be:
Captured continuously
Analyzed as they arrive
Acted upon immediately when needed
This is what enables early intervention.
Before a slowdown becomes noticeable.
Before a failure becomes disruptive.
Closing the Loop
Most systems stop at detection.
They identify that something is off and pass it on.
That’s only half the problem.
The real value comes from what happens next.
Once a pattern is recognized, the system needs to:
Determine the most likely cause
Decide whether action is required
Execute corrective steps
Observe the outcome
Learn from the result
This creates a feedback loop.
And over time, that loop becomes more accurate.
Operating at Scale
Handling millions of signals daily is not just about processing power.
It’s about consistency.
The system needs to behave reliably across:
Different device types
Different usage patterns
Different environments
It also needs to scale without introducing delays or inconsistencies.
Which means:
Distributed processing
Efficient data pipelines
Resilient infrastructure
Continuous optimization
All of this sits behind what appears, from the outside, to be a simple outcome.
Things just work.
Where This Shows Up in Practice
In a live environment, this translates into small but meaningful differences.
Devices that don’t gradually slow down over time
Issues that resolve before users notice them
Fewer recurring problems across the fleet
More consistent performance across different conditions
These are not dramatic changes.
They are subtle improvements that compound.
The Less Visible Impact
One of the more interesting effects of this approach is what doesn’t happen.
Fewer tickets are created
Fewer escalations are needed
Fewer interruptions occur
Over time, this changes how teams operate.
Less time reacting.
More time building.
Why This Matters
The complexity of endpoint environments is only increasing.
More devices.
More applications.
More variability.
Managing this manually doesn’t scale.
Even managing it with better visibility has limits.
At some point, the system itself needs to take on more responsibility.
Final Thought
It’s easy to measure what a system shows you.
It’s harder to measure what it quietly takes care of.
Processing millions of signals is not the goal.
The goal is what that processing enables.
Fewer issues.
Less disruption.
A system that improves over time without demanding constant attention.
That’s where things start to feel different.


