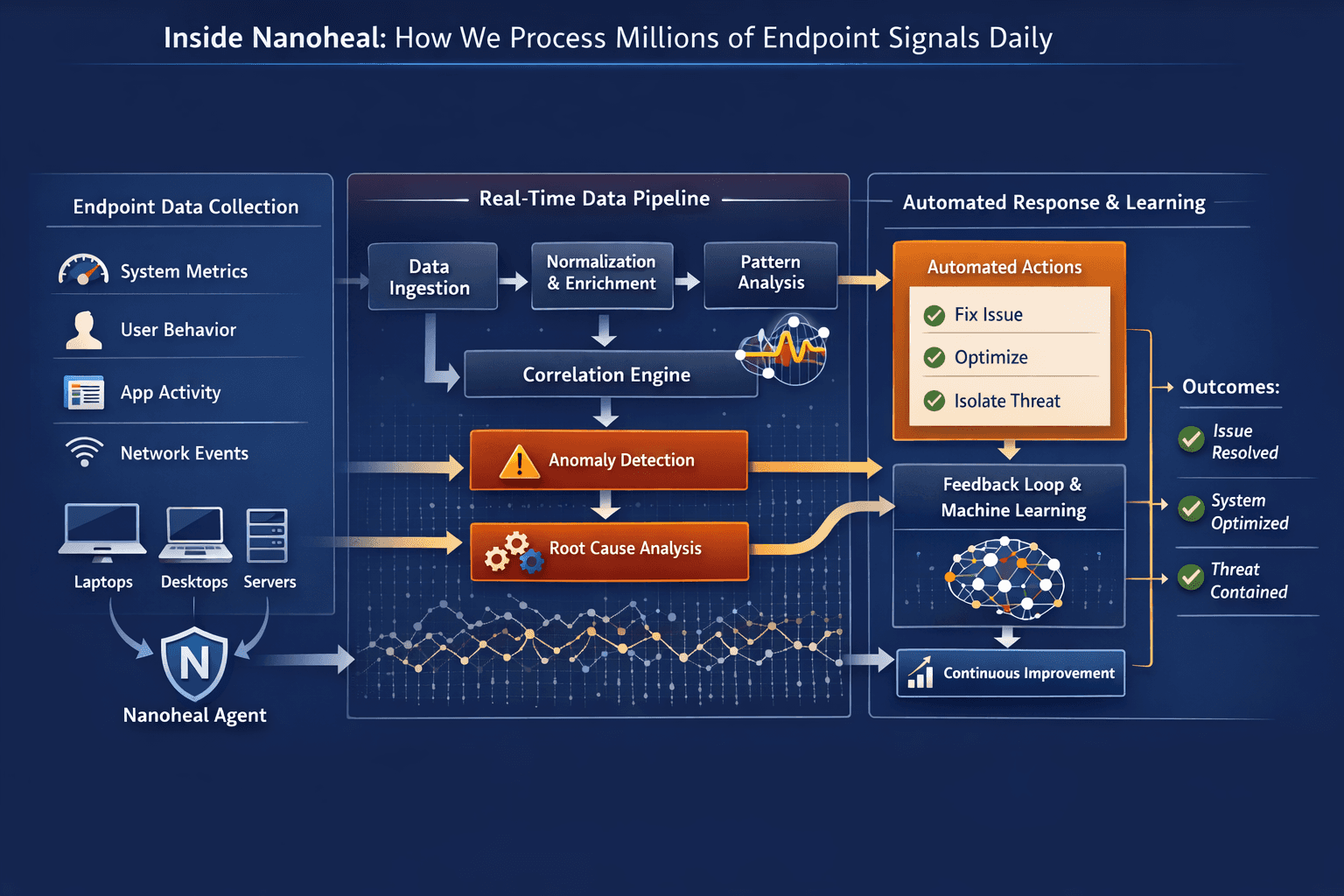
Ask most IT teams how they define a “healthy” device and you’ll get a familiar list.
CPU usage.
Memory consumption.
Disk space.
Boot time.
Patch status.
All useful. None complete.
Because a device can look perfectly fine on paper and still deliver a poor experience in practice.
That’s the gap.
The Problem with Traditional Metrics
Most endpoint metrics were designed for systems, not users.
They answer questions like:
Is the system within acceptable thresholds?
Are resources being overutilized?
Is the device technically compliant?
What they don’t answer is:
Is this device actually working well for the person using it?
A laptop running at 60% CPU might be “healthy” by traditional standards.
But if the user experiences lag, delays, or instability, that classification is meaningless.
Health, in this context, is not a system state.
It’s an experience outcome.
When “Green” Doesn’t Mean Good
One of the most common failure modes in endpoint management is false confidence.
Dashboards show green across the board.
No alerts are triggered.
Systems are “within limits.”
And yet, users complain.
Or worse, they stop complaining and just work around the problem.
Restarting machines multiple times a day
Avoiding certain applications
Delaying updates
Using personal devices for critical work
These are not edge cases. They are signals.
Signals that traditional metrics are missing something important.
Health Is a Pattern, Not a Snapshot
A single metric at a single point in time doesn’t tell you much.
Real device health emerges over time.
Does performance degrade after a few hours?
Do certain applications consistently cause slowdowns?
Are there recurring spikes linked to specific behaviors?
Does the system recover automatically, or does it require intervention?
This is where most tools fall short.
They measure states.
They don’t understand patterns.
And without patterns, you can’t predict or prevent issues.
Beyond Resource Monitoring
A more useful definition of device health includes:
Consistency of performance over time
Stability under real usage conditions
Frequency of recurring issues
Deviation from normal behavior patterns
Impact on user workflows
This shifts the focus from “is something wrong right now” to:
“Is this device trending toward a problem?”
That’s a very different question.
And a far more valuable one.
The Case for a Device Health Score
To make this actionable, you need a way to combine multiple signals into something coherent.
Not another dashboard with 50 charts.
A single, meaningful representation of health.
A Device Health Score should reflect:
Current performance
Historical stability
Behavioral anomalies
Risk of future issues
Most importantly, it should be dynamic.
A device that was healthy yesterday may not be healthy today.
And a device that looks fine right now may be trending toward failure.
Static metrics can’t capture that.
Where Most Implementations Go Wrong
Many tools attempt to create a “health score” by aggregating basic metrics.
CPU + memory + disk + patch status = score.
That’s just a summary, not intelligence.
It still relies on predefined thresholds.
It still misses contextual behavior.
It still reacts after the fact.
A meaningful health model needs to understand:
What’s normal for this device
What’s normal for this user
What’s normal for this environment
Anything outside that baseline is where the signal lies.
Where Nanoheal Fits In
Nanoheal approaches device health as a living system, not a checklist.
Instead of relying on static thresholds, it builds a behavioral understanding of endpoints:
Tracking how devices perform over time
Identifying deviations from normal usage patterns
Detecting early signs of degradation
Correlating system, application, and user-level signals
This allows Nanoheal to move beyond reporting health to actively maintaining it.
When a device starts trending toward a problem:
Resource imbalances are corrected
Configuration drift is resolved
Recurring issues are addressed automatically
The result is not just visibility into health.
It’s continuous health optimization.
Rethinking What “Good” Looks Like
A healthy device is not one that meets technical thresholds.
It’s one that:
Performs consistently throughout the day
Doesn’t require user intervention to stay functional
Doesn’t generate recurring issues
Doesn’t degrade over time
In other words, a device that stays out of the way.
Final Thought
The industry has spent years measuring what’s easy.
CPU. Memory. Disk.
But the real question has always been harder.
Is the device actually delivering a good experience?
Once you start answering that question properly, everything else changes.
Because now you’re not just monitoring systems.
You’re managing outcomes.